From OCR to Agents: The Evolution of Invoice Processing at Ringil
At Ringil, we build Transportation Management Systems (TMS) and Timeslot management solutions that digitize chaotic supply chains.

Our platform connects shippers with carriers, handling everything from transport orders to yard management.
But digital logistics has a messy analog bottleneck: The Invoice.
Carriers send invoices in every conceivable format: PDFs, scanned images, photos taken on truck hoods, or complex multi-page excels. For a TMS to be useful, it must validate these invoices against the original Transport Order (agreed price vs. charged price, verifying surcharges like waiting times).
For years, this meant humans manually typing data. This article details how we automated this bottleneck, evolving from brittle templates to a self-correcting Agentic IDP (Intelligent Document Processing) architecture.
The Problem: Logistics is “Messy”
Invoices are the API of the analog world. But unlike REST APIs, they have no schema.
Variety: We deal with thousands of carriers, each with a unique layout.
Complexity: A logistics invoice isn’t just a total. It includes “Demurrage Fees,” “Waiting Time,” and dual-currency calculations.
Quality: Scans are often rotated, blurry, or coffee-stained.
Why Legacy OCR Failed Us
We evaluated the entire history of document processing technologies. Here is why the old ways didn’t work for Ringil.
1. Template-Based & Zone OCR (The Rigid Era)
Tools like Abbyy FlexiCapture or open-source solutions defined this era. You draw a bounding box on a template saying “The total is always in the bottom right.”
The Fail: In logistics, you can’t build 5,000 templates for 5,000 carriers. If a carrier adds a logo and shifts the text down by 2cm, the extraction fails.
2. Cloud AI (The Black Box Era)
Services like Amazon Textract or Google Document AI introduced deep learning to recognize “Tables” and “Forms” without templates. They significantly improved raw text extraction quality, but scaling them across thousands of long-tail logistics invoices proved costly and operationally heavy. While custom schemas and trained processors can extract additional fields, each new carrier layout or pricing nuance often requires retraining, relabeling, or rule maintenance. At Ringil’s with evolving invoice formats—this approach became brittle to operate, even if the underlying OCR was accurate.
The Solution: Agentic Extraction
We moved to an Agentic Architecture. Instead of just “reading” text, we use Large Language Models (LLMs) to “reason” over the document.
1. Vision-First Ingestion with OCR Sidecar
Traditional OCR flattens a 2D document into a 1D stream of text. This destroys spatial context—knowing that a number is under the “Tax” column is as important as the number itself.
We use Multimodal LLMs (like Google Gemini 3.0 Flash) that natively “see” the document image.
The Problem: Vision models are excellent at layout, but can hallucinate on blurry or compromised text (e.g., misreading a fuzzy “8” as “3”).
The Fix (The “Sidecar”): We inject high-fidelity text extracted by Mistral-OCR (with DeepSeek as fallback). We construct the prompt with both inputs:
if ocr_text:
ocr_section = (
f"\n\n[OFFICIAL OCR TRANSCRIPTION START]\n"
f"{ocr_text}\n"
f"[OFFICIAL OCR TRANSCRIPTION END]\n"
f"INSTRUCTION: Use the above OCR text as the PRIMARY source for specific numbers "
f"(IBANs, Dates, Amounts) to avoid optical hallucinations. "
f"Use the image visuals for layout context only."
)
prompt += ocr_sectionThis combination gives us the best of both worlds: the model uses the image for layout understanding (identifying table boundaries, grouping related fields) and the OCR text as a character-level lookup dictionary (copying exact IBANs, amounts, dates without optical errors).
Important clarification: We don’t provide spatial coordinates mapping OCR text to pixel regions. Instead, we rely on the model’s ability to semantically match content—when it sees “Total: €2,045.46” in the image, it searches the OCR text for the corresponding value. This works because invoice fields are often contextually unambiguous after domain constraints are applied.
2. Structured Enforcement with Pydantic
LLMs are creative, which is dangerous for data entry. We enforce structure using Pydantic models with built-in validators.
Why Not BAML? We evaluated BAML (Boundary ML), a domain-specific language designed specifically for structured LLM outputs. BAML offers elegant syntax and built-in retry logic, but we chose Pydantic for several reasons:
Ecosystem Integration: Our codebase is already Python-native. Pydantic models integrate seamlessly with FastAPI, our validation engine, and MLflow logging—no transpilation step or additional tooling required.
Custom Validators: Logistics invoices require domain-specific validation (VAT pattern matching, currency conversion tolerance checks, date consistency). Pydantic’s
@model_validatorand@field_validatordecorators let us embed this logic directly in the schema.Runtime Flexibility: We dynamically adjust validation strictness based on carrier history and document quality. Pydantic’s programmatic access to validation errors gives us fine-grained control over the repair loop.
Team Familiarity: Every Python developer knows Pydantic. BAML introduces a new DSL with its own learning curve—a tax we didn’t want to pay for a team already proficient in Python typing.
BAML is a promising tool for greenfield projects, but for our existing Python infrastructure, Pydantic offered the right balance of power and pragmatism.
Our actual InvoiceResponse model handles dual-currency invoices common in European logistics:
from pydantic import BaseModel, Field, model_validator
from typing import List, Optional
class TransportDetails(BaseModel):
line_items: Optional[List[str]] = Field(default_factory=list)
amount_without_tax: Optional[float] = Field(None, ge=0)
amount_with_tax: Optional[float] = Field(None, ge=0)
currency: Optional[str] = None
class InvoiceResponse(BaseModel):
# Dual currency support (common in EU logistics)
currency_1: Optional[str] = None # Customer's home currency
currency_2: Optional[str] = None # Carrier's currency
total_amount_without_tax_currency_1: Optional[float] = Field(None, ge=0)
total_amount_with_tax_currency_1: Optional[float] = Field(None, ge=0)
tax_rate: Optional[float] = Field(None, ge=0, le=1)
tax_absolute_value_currency_1: Optional[float] = Field(None, ge=0)
currency_rate: Optional[float] = Field(None, gt=0)
# Carrier identification
carrier_tax_number: Optional[str] = None
bank_iban: Optional[str] = None
# Line items
transport_details: Optional[List[TransportDetails]] = Field(default_factory=list)
# Validation warnings
warnings: Optional[List[str]] = Field(default_factory=list)
@model_validator(mode='after')
def validate_currency_consistency(self):
"""Validate currency-related fields consistency."""
warnings = self.warnings or []
if self.currency_1 and self.total_amount_without_tax_currency_1 is not None and self.total_amount_with_tax_currency_1 is not None:
if self.total_amount_with_tax_currency_1 < self.total_amount_without_tax_currency_1:
warnings.append("Currency 1: Amount with tax is less than amount without tax")
if self.tax_absolute_value_currency_1 is not None:
expected_total = self.total_amount_without_tax_currency_1 + self.tax_absolute_value_currency_1
if abs(expected_total - self.total_amount_with_tax_currency_1) > 0.01:
warnings.append("Currency 1: Tax calculation inconsistency detected")
self.warnings = warnings
return selfConnecting Pydantic to the Repair Loop: Our orchestration layer triggers repairs based on both Pydantic warnings and a separate _compute_issues() function that runs additional business rules. If either mechanism produces issues (e.g., len(response.warnings) > 0 with critical markers, or business rule violations), we escalate to the repair path. This separation lets Pydantic handle schema enforcement while business logic handles domain-specific validation.
3. The “Self-Healing” Validation Loop
This is where “Extraction” becomes “Agentic.” We don’t just accept the model’s first answer. We implement a Validator-Repair Loop with tiered escalation.
┌───────────────────┐ ┌─────────────────┐ ┌─────────────┐
│ Extract │────▶│ Compute Issues │────▶│ No Issues? │───▶ Done
│ (Gemini 3 Flash) │ │ │ └─────────────┘
└───────────────────┘ └─────────────────┘ │
│ Issues Found
▼
┌─────────────────┐ ┌──────────────────────────┐
│ Still Issues? │◀────│ Repair │
│ │ │ (GPT-4o/Gemini 2.5 Pro) │
└─────────────────┘ └──────────────────────────┘
│
│ Escalate
▼
┌─────────────────────────┐
│ Final: Code Execution │
│ (Gemini + Python) │
└─────────────────────────┘The flow works as follows:
Extract with Gemini 3 Flash preview produces the initial structured output
Compute Issues runs our deterministic business rule validators (currency consistency, date ordering, etc.)
If issues are found, we escalate to GPT-4o for repair—a stronger reasoning model that re-examines the document with explicit error context
If GPT-4o still can’t resolve the issues, we make a final escalation to Gemini 3 flash preview with Code Execution enabled
Our validation engine checks multiple business rules before accepting any extraction:
Currency & Amount Rules:
In case of multi-currency invoice, amounts have to be available in all currencies
Both taxed and untaxed totals need to be extracted
Multiple amounts extracted (suggesting multi-currency invoice) but currency symbol not found or in wrong format
Tax rate has to be extracted
For multi-currency invoice currency conversion rate is mandatory
Currency conversion rate has to match the ratio of totals (±10% tolerance)
Currency codes have to be valid 3-letter ISO codes
Date Validation:
Invoice date earlier than or equal to Due date
Taxable supply date earlier than or equal to Invoice date
Carrier Identification:
Carrier country is mandatory and has to be valid ISO alpha-2 code
Carrier tax number is mandatory matches known VAT patterns
Extracted Carrier (Supplier) name is different from extracted Customer name
Line Item Integrity:
Transport details have to sum to invoice totals (±0.01 tolerance)
Line item are all in same currency
Mandatory fields on line level: Currency symbol, Taxed amount, Non-Taxed amount, Line reference
When issues are found, we build a multimodal repair prompt that includes both the original document and the specific detected issues. The model receives the current JSON, a list of what’s wrong, and re-examines the source document to produce corrections.
4. The Model Mesh (Multi-Provider Fallback)
We don’t rely on a single AI provider. We configure a tiered model mesh (see below).
This comes with real operational complexity—different providers have different vision strengths, output styles, and failure modes. To manage this, we standardize prompts, normalize outputs through strict schemas, and continuously track provider-specific performance in MLflow. Fallbacks are not the common path, but they ensure resilience during outages and edge cases without blocking invoice ingestion.

For each stage (extraction, repair-lite, final-repair) we applied series of fallbacks. As for each stage it can happen that some provider fill fail (e.g. due to general outage), then the process will continue with contingency provider. For example for Extraction stage we start with gemini-3-flash-preview, but if this provider is out, the process will fail over to gemini-2.5-flash, if this one is out as well, process will try gpt-4o. And often extraction will continue the normal process of validation and repairs.
5. Code Execution for Mathematical Validation
LLMs are notoriously unreliable at arithmetic. A model might correctly read “Base: €1,000” and “Tax: 21%” but hallucinate “Total: €1,250” instead of €1,210. In such cases the validation stage would fail and we would apply repair step with thinking models such as gpt-4o. Sometimes the invoice is so messy/complex that even gpt-4o is not able to extract the information correctly. In those cases process fails over to 2nd (final) level of repairs employing Gemini 3 flash preview with Gemini’s Code Execution tool enabled and Thinking level set to High.
For the final validation step, we enable Gemini’s Code Execution capability:
# Final repair attempt with code execution enabled and thinking level set to high
thinkingConfig=genai_types.ThinkingConfig(
thinkingLevel=genai_types.ThinkingLevel.HIGH
),
tools=[genai_types.Tool(code_execution=genai_types.ToolCodeExecution())]This allows the model to write and execute Python code to verify calculations:
Sum transport line items and compare to totals
Calculate tax from base amount and rate
Verify currency conversion at the declared exchange rate
Instead of guessing that 2045.46 × 1.21 = 2475.00, the model runs the calculation. Code execution runs in Gemini’s sandboxed environment with no access to external systems or customer data.
Limitation to acknowledge: Code Execution validates internal mathematical consistency, not ground truth. If the model hallucinates the inputs (e.g., reads “Tax: 21%” when the document says “Tax: 10%”), it will write code that calculates Base × 0.21—mathematically correct, but factually wrong. Code execution eliminates “LLM arithmetic errors” (where the model correctly reads inputs but fumbles the sum), but it cannot prove the numbers match the pixels. That’s why we combine it with the OCR sidecar and multimodal validation.
6. API Resilience Patterns
Cloud APIs fail. We implement defensive patterns:
Timeouts: 90-second hard limit on all LLM calls to prevent indefinite hangs
Circuit breaker: After consecutive failures, skip provider for cooldown period
Graceful degradation: If all providers fail, return partial result with warnings
# All Gemini calls wrapped with timeout
response = await asyncio.wait_for(
asyncio.to_thread(client.models.generate_content, ...),
timeout=90, # Prevents infinite hangs from server disconnects
)Evaluation & MLOps
LLMs are non-deterministic. We treat prompt engineering like software engineering with rigorous evaluation.
Why MLflow over LangSmith? We considered several LLMOps platforms:
LangSmith (LangChain): Excellent tracing and prompt versioning, but tightly coupled to the LangChain ecosystem. We use raw API calls with custom orchestration—LangSmith’s value diminishes without LangChain abstractions.
Weights & Biases (W&B): Great for ML experimentation, but its LLM-specific features (Prompts, Traces) felt bolted-on compared to native experiment tracking.
Braintrust, Humanloop, PromptLayer: Purpose-built for LLM eval, but add vendor lock-in and per-seat pricing that scales poorly.
We chose MLflow because:
Self-hosted: Runs on our infrastructure with full data sovereignty—critical for enterprise customers.
Experiment-first: Native support for comparing runs, tracking metrics over time, and storing artifacts (our per-invoice deltas).
Framework-agnostic: Works with any LLM provider without wrapper libraries.
Cost: Free and open-source. At scale, LangSmith’s usage-based pricing becomes material.
MLflow Experiment Tracking
Every prompt change, model swap, or pipeline modification is tracked as an MLflow run. We store:
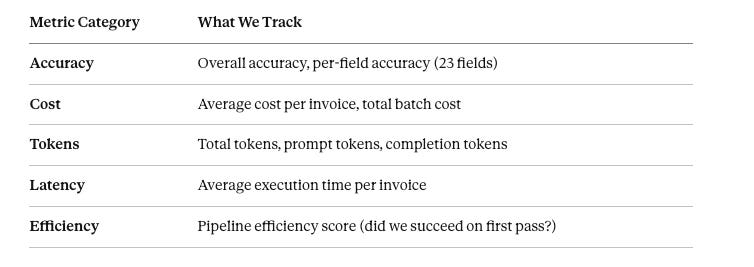
Field-Level Accuracy uses different comparison strategies:
Exact match: IBANs, VAT numbers, invoice numbers
Fuzzy match: Carrier names (90% similarity threshold using RapidFuzz)
Numeric tolerance: Amounts (±0.01), tax rates
Date normalization: Parse multiple formats before comparison
In MLflow artifacts, we store per-invoice deltas so we can drill down into specific failures—if accuracy drops, we can see exactly which invoice and which field failed.
Pipeline Efficiency Tracking
Accuracy alone doesn’t tell the full story. A system that achieves 95% accuracy but requires expensive repairs on every invoice isn’t sustainable.
We score pipeline efficiency based on the execution path:
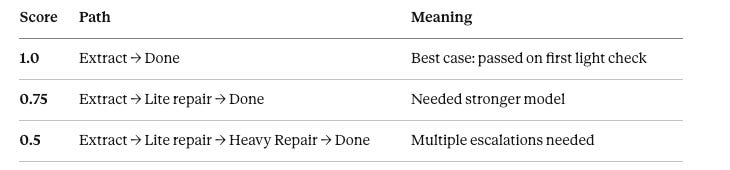
Why this matters: If efficiency drops from 0.9 to 0.6, it means more invoices are entering the repair path—even if final accuracy stays high. This signals prompt degradation or a new invoice pattern the extraction model struggles with.
Currently, 88% of invoices pass directly after extraction (efficiency = 1.0), while 12% require the repair path. Of those requiring repair, most are successfully corrected, yielding the 94.37% document-level accuracy reported below.
Accuracy & Performance
The ultimate measure of an extraction system is accuracy. Here’s how our Agentic IDP performs on real-world logistics invoices.
Test Set Composition
We evaluate against a held-out test set of 146 real-world invoices, annotated by domain experts and intentionally skewed toward difficult layouts and quality issues. While this dataset is not exhaustive, it reflects the operational diversity we see in production today and serves as a continuously expanding benchmark as new carriers onboard.
Across these documents, we extract 23 fields per invoice, yielding a total of 3,504 extracted values in our test set.
Current Accuracy
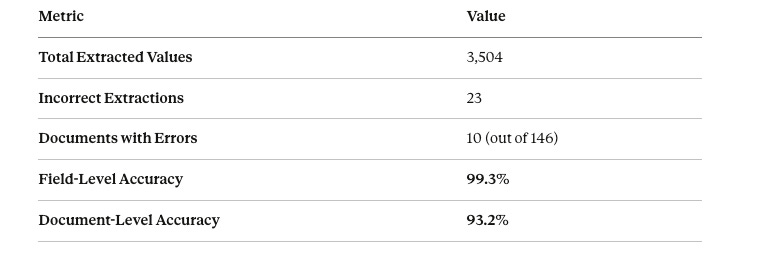
The 23 incorrectly extracted fields are distributed across just 10 documents—typically edge cases with unusual formatting or ambiguous line items. The remaining 136 documents (93.2%) achieve perfect extraction across all 23 fields.

The 40-second average includes OCR sidecar generation, multimodal extraction, validation, and any repair passes. Documents that pass on the first attempt complete in ~25 seconds; those requiring GPT-4o repair add ~15-20 seconds.
Importantly, invoices are processed asynchronously—users don’t wait after upload. Multiple invoices are processed in parallel, and once extraction completes, the structured data is automatically pushed to the customer’s system. The 40-second latency is amortized across background workflows and has no impact on operator throughput.
Error Analysis
When extraction fails, it’s typically due to:
Ambiguous line items: Invoices with multiple transport legs where totals are split non-obviously
Very poor invoice quality: Blurred or very poorly scanned documents that confuse the layout understanding
These edge cases feed back into prompt refinement and validation rule updates.
Security & Enterprise Readiness
“Are you training on our data?” is the first question our Enterprise customers ask.
Data Protection: We use Enterprise API tiers (Google Vertex AI, OpenAI Enterprise, Mistral Platform). Provider contracts explicitly prohibit training on customer data. Documents are retained only for the processing window before being discarded.
Strict Schemas: Pydantic enforces structural correctness and type safety, preventing entire classes of errors where extracted values land in incompatible fields (for example, text appearing in numeric tax fields). While schema validation cannot guarantee semantic correctness on its own, it acts as a critical guardrail—ensuring that only structurally valid data enters downstream business logic and repair workflows.
Cost Transparency: Every extraction includes a full
cost_breakdownfor audit and chargeback.
Conclusion: From Reading to Reasoning
The evolution from OCR to Agents is a shift from “finding text” to “understanding business logic.”
At Ringil, this allows us to onboard new carriers instantly. There are no templates to build, no zones to draw. We just show the Agent the invoice, and it figures it out—just like a human would, only faster.
Zuzana Szabová
Head of Data Ringil
Ale ešte jedna vec k tomu artiklu teraz:
`We use Enterprise API tiers (Google Vertex AI, OpenAI Enterprise, Mistral Platform). Provider contracts explicitly prohibit training on customer data. Documents are retained only for the processing window before being discarded.`
Sa nedá brať vážne, lebo celá AI bublina je jedna banda podvodníkov a tí budú aj tak skrachovaní keď praskne, čiže to, čo sa s nimi dohodne je null-and-void aj tak.
`Strict Schemas: Pydantic enforces structural correctness and type safety, preventing entire classes of errors where extracted values land in incompatible fields (for example, text appearing in numeric tax fields). While schema validation cannot guarantee semantic correctness on its own, it acts as a critical guardrail—ensuring that only structurally valid data enters downstream business logic and repair workflows.`
Bu Bu Bu ... na to nepotrebujem ani riešiť nič v appke, stačí, že mám tieto typy dobre zadané v SQL databanke, do ktorej to potom dávam. Tam by mi to buchlo tiež, keď by dával varchar do integera a podobne, takisto sa dajú aj v SQL spraviť CHECK bullshit-protectory.
`Cost Transparency: Every extraction includes a full cost_breakdown for audit and chargeback.`
Áno? Ja by som povedal, že to je radar na exekútorského úradníka, ktorý bude všetky AI firmy naháňať pre tie sekery, ktoré voči investorom zanechali.
S týmto by sa mi ľahko prišlo aj samému, lebo niečo podobné som aj ja robil, ale nie s faktúrami.
Flat scanner sa dá ľahko s `while true`; do sleep 10; scan_that_thing; done prehovoriť k tomu, aby spustil `scanimage`a výsledok pipe-ol do tesseractu, ktorý vyextrahuje text, ktorý potom cez pipe hodím rovno do grep -oE 'spolu na úhradu [^€]+ €' vybavené. A nemusím nič programovať.
Ja som ale scanoval "právne" dokumenty, tak som to po tesseracte ešte nehal prehnať do hunspell, lebo tam už vychytá niektoré zle rozpoznané symboly na kontrole pravopisu.
Ak je na faktúre PayBySquare, tak sa dá jednoducho cez ImageMagick crop filtrom odrezať cirka len miesto, kde sa nachádza ten QR code, ktorý nás zaujíma, aby sme nezobrali nejaký vedľa, a potom ten výstup (napr PNG, alebo TIFF) trepneme rovno do zbar a ten ti potom vyklepne ten JSON, čo fakticky PayBySquare je, špecifikácia je na githube, cez ten ich python modul vidíme ako sa to skladá a tento JSON potom môžem rovno prevziať do systému, tie položky, ktoré treba (ako IBAN a sumu atď).
Ono toto nie je nič nové. SAP má nejaký modul, kde im človek na jeden mail posiela faktúry ako invoice@example.com a potom ten to číta cez IMAP, vyťahuje z toho PDF a té hádže rovno do pdftotext, aby mal text a tam potom sa pokračuje cez grep, čo má výhodu, že tam nemáme nepresnosti OCRka. Ale aj tak je to na hovno, keď tam príde nejaký rozbitý PDF, tak to je potom tiež nespoľahlivé a preto si vymysleli ten eInvoicing, čo oni za to lobbovali, aby sa to dalo do EU-lex, aby to museli všetci posielať cez XML a tým pádom celý takýto byznis model padá.
XML si každý už parsne ako DOM a potom tam môže lietať cez findElement, ako pri HTML.
Čo tým ale chcem povedať je, že žiadne AI netreba a to je vyhodená energia a penáze (hlavne).
Ja som nad takým rozmýšlal už dávno a to sú tie dôvody prečo som do toho nešiel už 10 rokov dozadu, lebo tie problémy zostali tie isté a akonáhle sa invoicuje cez XML padá všetko (2027).